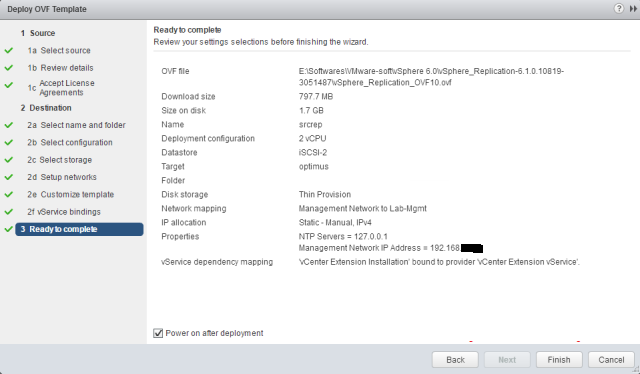
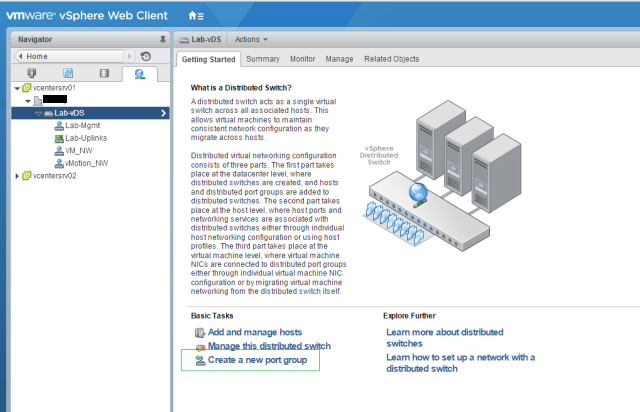
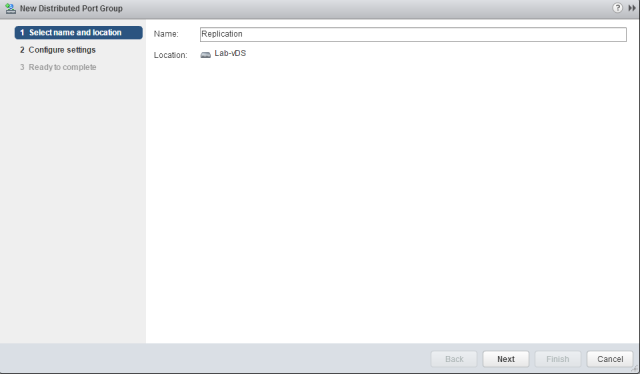
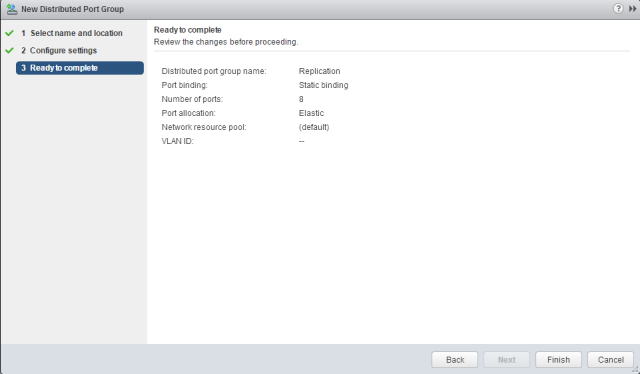
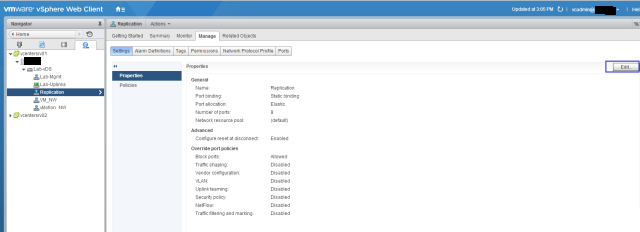
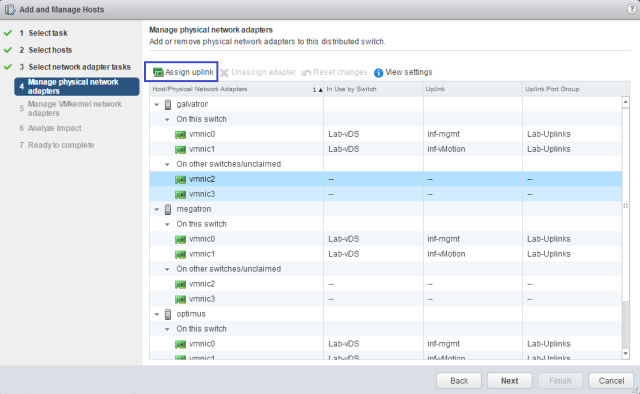
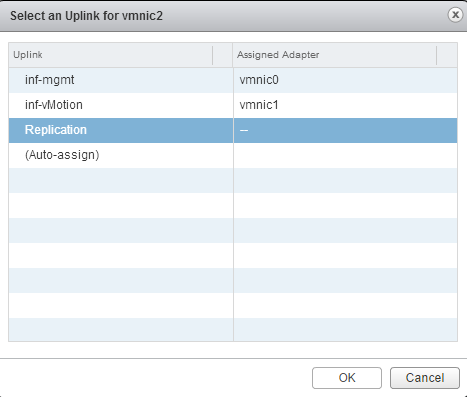
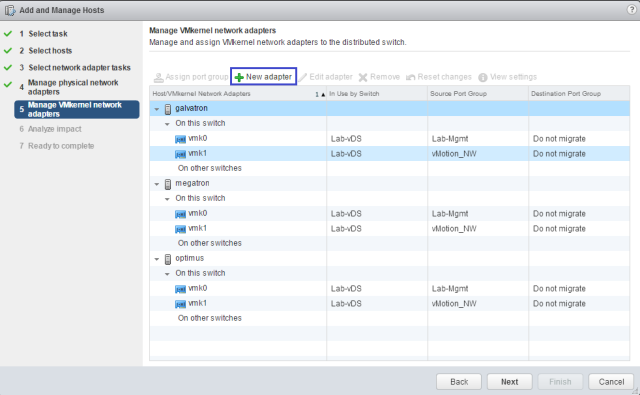
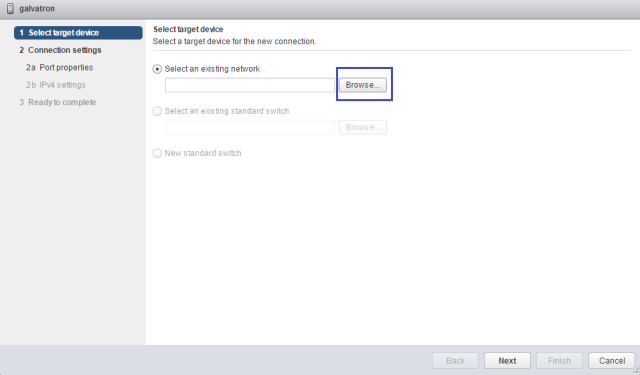
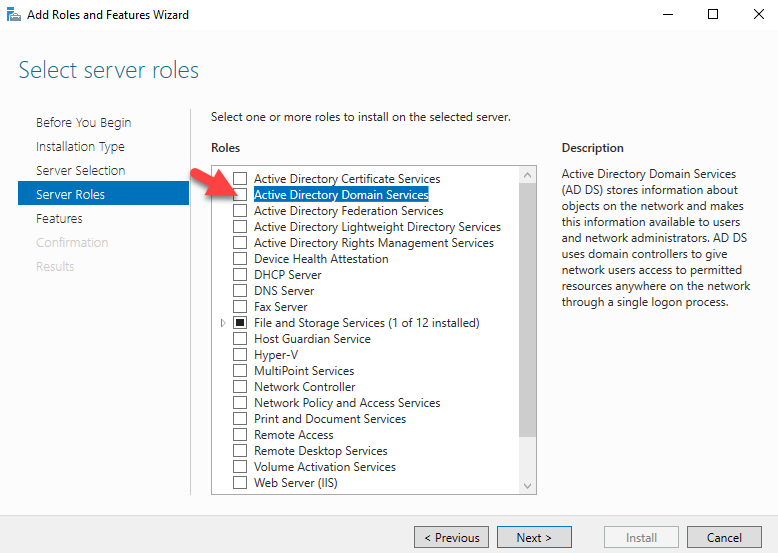
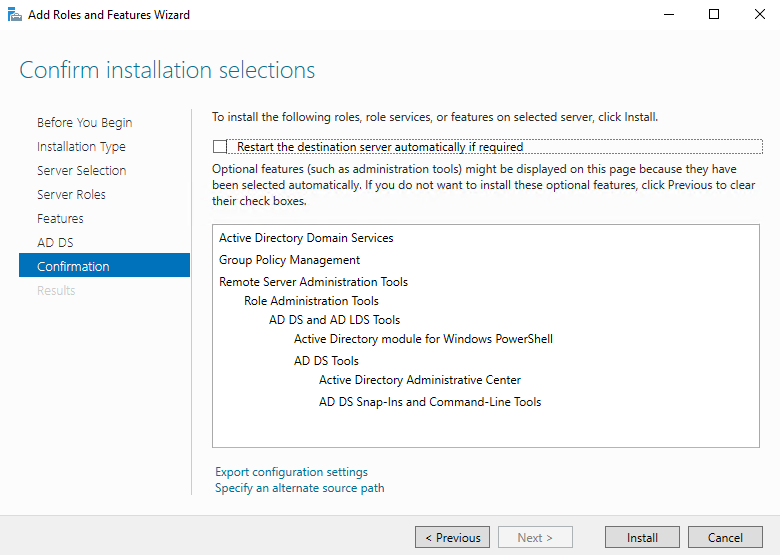
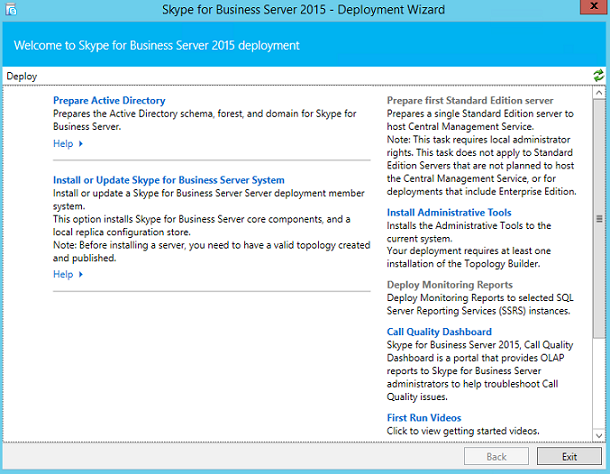
Sysdig is open source, system-level exploration: capture system state and activity from a running Linux instance, then save, filter and analyze. Sysdig is scriptable in Lua and includes a command line interface and a powerful interactive UI, csysdig, that runs in your terminal.
This article will guide you through the steps to install and configure Sysdig to monitor an Ubuntu 16.04 server as an example using Sysdig.
Installing Sysdig Using the Official Script
There's a Sysdig package in the Ubuntu repository, but it's usually a revision or two behind the current version. At the time of publication, for example, installing Sysdig using Ubuntu's package manager will get you Sysdig 0.8.0. However, you can install it using an official script from the project's development page, which is the recommended method of installation. This is the method we'll use.
But first, update the package database to ensure you have the latest list of available packages:
sudo apt-get update
Now download Sysdig's installation script with curl using the following command:
curl https://s3.amazonaws.com/download.draios.com/stable/install-sysdig -o install-sysdig
This downloads the installation script to the file install-sysdig to the current folder. You'll need to execute this script with elevated privileges, and it's dangerous to run scripts you download from the Internet. Before you execute the script, audit its content by opening it in a text editor or by using the less command to display the contents on the screen:
less ./install-sysdig
Once you're comfortable with the commands the script will run, execute the script with the following command:
cat ./install-sysdig | sudo bash
The command will install all dependencies, including kernel headers and modules. The output of the installation will be similar to the following:
Output
* Detecting operating system
* Installing Sysdig public key
OK
* Installing sysdig repository
* Installing kernel headers
* Installing sysdig
...
sysdig-probe:
Running module version sanity check.
- Original module
- No original module exists within this kernel
- Installation
- Installing to /lib/modules/4.4.0-59-generic/updates/dkms/
depmod....
DKMS: install completed.
Processing triggers for libc-bin (2.23-0ubuntu5) ...
Now that you've got Sysdig installed, let's look at some ways to use it.
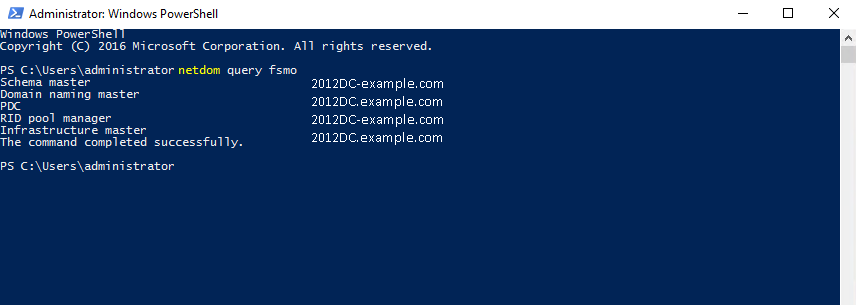
Monitoring Your System in Real-TimeIn this section, you'll use the sysdig command to look at some events on your Ubuntu 16.04 server. The sysdig command requires root privileges to run, and it takes any number of options and filters. The simplest way to run the command is without any arguments. This will give you a real-time view of system data refreshed every two seconds:
sudo sysdigBut, as you'll see as soon as you run the command, it can be difficult to analyze the data being written to the screen because it streams continuously, and there are lots of events happening on your server. Stop sysdig by pressing CTRL+C.
Before we run the command again with some options, let's get familiar with the output by looking at a sample output from the command:
Output
253566 11:16:42.808339958 0 sshd (12392) > rt_sigprocmask
253567 11:16:42.808340777 0 sshd (12392) < rt_sigprocmask
253568 11:16:42.808341072 0 sshd (12392) > rt_sigprocmask
253569 11:16:42.808341377 0 sshd (12392) < rt_sigprocmask
253570 11:16:42.808342432 0 sshd (12392) > clock_gettime
253571 11:16:42.808343127 0 sshd (12392) < clock_gettime
253572 11:16:42.808344269 0 sshd (12392) > read fd=10(/dev/ptmx) size=16384
253573 11:16:42.808346955 0 sshd (12392) < read res=2 data=..
The output's columns are:
Output
%evt.num %evt.outputtime %evt.cpu %proc.name (%thread.tid) %evt.dir %evt.type %evt.info
Here's what each column means:
- evt.num is the incremental event number.
- evt.outputtime is the event timestamp, which you can customize.
- evt.cpu is the CPU number where the event was captured. In the above output, the evt.cpu is 0, which is the server's first CPU.
- proc.name is the name of the process that generated the event.
- thread.tid is the TID that generated the event, which corresponds to the PID for single thread processes.
- evt.dir is the event direction. You'll see > for enter events and < for exit events.
- evt.type is the name of the event, e.g. 'open', 'read', 'write', etc.
- evt.info is the list of event arguments. In case of system calls, these tend to correspond to the system call arguments, but that’s not always the case: some system call arguments are excluded for simplicity or performance reasons.
There's hardly any value in running sysdig like you did in the previous command because there's so much information streaming in. But you can apply options and filters to the command using this syntax:
sudo sysdig [option] [filter]
You can view the complete list of available filters using:
sysdig -l
There's an extensive list of filters spanning several classes, or categories. Here are some of the classes:
- fd: Filter on file descriptor (FD) information, like FD numbers and FD names.
- process: Filter on process information, like id and name of the process that generated an event.
- evt: Filter on event information, like event number and time.
- user: Filter on user information, like user id, username, user's home directory or login shell.
- group: Filter on group information, like group id and name.
- syslog: Filter on syslog information, like facility and severity.
- fdlist: Filter on file descriptor for poll events.
Since it's not practical to cover every filter in this tutorial, let's just try a couple, starting with the syslog.severity.str filter in the syslog class, which lets you view messages sent to syslog at a specific severity level. This command shows messages sent to syslog at the "information" level:
sudo sysdig syslog.severity.str=info
Kill the command by pressing CTRL+C.
The output, which should be fairly easy to interpret, should look something like this:
Output
10716 03:15:37.111266382 0 sudo (26322) < sendto syslog sev=info msg=Jan 24 03:15:37 sudo: pam_unix(sudo:session): session opened for user root b
618099 03:15:57.643458223 0 sudo (26322) < sendto syslog sev=info msg=Jan 24 03:15:57 sudo: pam_unix(sudo:session): session closed for user root
627648 03:16:23.212054906 0 sudo (27039) < sendto syslog sev=info msg=Jan 24 03:16:23 sudo: pam_unix(sudo:session): session opened for user root b
629992 03:16:23.248012987 0 sudo (27039) < sendto syslog sev=info msg=Jan 24 03:16:23 sudo: pam_unix(sudo:session): session closed for user root
639224 03:17:01.614343568 0 cron (27042) < sendto syslog sev=info msg=Jan 24 03:17:01 CRON[27042]: pam_unix(cron:session): session opened for user
639530 03:17:01.615731821 0 cron (27043) < sendto syslog sev=info msg=Jan 24 03:17:01 CRON[27043]: (root) CMD ( cd / && run-parts --report /etc/
640031 03:17:01.619412864 0 cron (27042) < sendto syslog sev=info msg=Jan 24 03:17:01 CRON[27042]: pam_unix(cron:session): session closed for user
You can also filter on a single process. For example, to look for events from nano, execute this command:
sudo sysdig proc.name=nano
Since this command filers on nano, you will have to use the nano text editor to open a file to see any output. Open another terminal editor, connect to your server, and use nano to open a text file. Write a few characters and save the file. Then return to your original terminal.
You'll then see some output similar to this:
Output
21840 11:26:33.390634648 0 nano (27291) < mmap res=7F517150A000 vm_size=8884 vm_rss=436 vm_swap=0
21841 11:26:33.390654669 0 nano (27291) > close fd=3(/lib/x86_64-linux-gnu/libc.so.6)
21842 11:26:33.390657136 0 nano (27291) < close res=0
21843 11:26:33.390682336 0 nano (27291) > access mode=0(F_OK)
21844 11:26:33.390690897 0 nano (27291) < access res=-2(ENOENT) name=/etc/ld.so.nohwcap
21845 11:26:33.390695494 0 nano (27291) > open
21846 11:26:33.390708360 0 nano (27291) < open fd=3(/lib/x86_64-linux-gnu/libdl.so.2) name=/lib/x86_64-linux-gnu/libdl.so.2 flags=4097(O_RDONLY|O_CLOEXEC) mode=0
21847 11:26:33.390710510 0 nano (27291) > read fd=3(/lib/x86_64-linux-gnu/libdl.so.2) size=832
Again, kill the command by typing CTRL+C.
Getting a real time view of system events using sysdig is not always the best method of using it. Luckily, there's another way - capturing events to a file for analysis at a later time. Let's look at how.
Capturing System Activity to a File Using Sysdig
Capturing system events to a file using sysdig lets you analyze those events at a later time. To save system events to a file, pass sysdig the -w option and specify a target file name, like this:
sudo sysdig -w sysdig-trace-file.scap
Sysdig will keep saving generated events to the target file until you press CTRL+C. With time, that file can grow quite large. With the -n option, however, you can specify how many events you want Sysdig to capture. After the target number of events have been captured, it will exit. For example, to save 300 events to a file, type:
sudo sysdig -n 300 -w sysdig-file.scap
Though you can use Sysdig to capture a specified number of events to a file, a better approach would be to use the -C option to break up a capture into smaller files of a specific size. And to not overwhelm the local storage, you can instruct Sysdig to keep only a few of the saved files. In other words, Sysdig supports capturing events to logs with file rotation, in one command.
For example, to save events continuously to files that are no more than 1 MB in size, and only keep the last five files (that's what the -W option does), execute this command:
sudo sysdig -C 1 -W 5 -w sysdig-trace.scap
List the files using ls -l sysdig-trace* and you'll see output similar to this, with five log files:
Output
-rw-r--r-- 1 root root 985K Nov 23 04:13 sysdig-trace.scap0
-rw-r--r-- 1 root root 952K Nov 23 04:14 sysdig-trace.scap1
-rw-r--r-- 1 root root 985K Nov 23 04:13 sysdig-trace.scap2
-rw-r--r-- 1 root root 985K Nov 23 04:13 sysdig-trace.scap3
-rw-r--r-- 1 root root 985K Nov 23 04:13 sysdig-trace.scap4
As with real-time capture, you can apply filters to saved events. For example, to save 200 events generated by the process nano, type this command:
sudo sysdig -n 200 -w sysdig-trace-nano.scap proc.name=nano
Then, in another terminal connected to your server, open a file with nano and generate some events by typing text or saving the file. The events will be captured to sysdig-trace-nano.scap until sysdig records 200 events.
How would you go about capturing all write events generated on your server? You would apply the filter like this:
sudo sysdig -w sysdig-write-events.scap evt.type=write
Press CTRL+C after a few moments to exit.
You can do a whole lot more when saving system activity to a file using sysdig, but these examples should have given you a pretty good idea of how to go about it. Let's look at how to analyze these files.
Reading and Analyzing Event Data with Sysdig
Reading captured data from a file with Sysdig is as simple as passing the -r switch to the sysdig command, like this:
sudo sysdig -r sysdig-trace-file.scap
That will dump the entire content of the file to the screen, which is not really the best approach, especially if the file is large. Luckily, you can apply the same filters when reading the file that you applied to it while it was being written.
For example, to read the sysdig-trace-nano.scap trace file you created, but only look at a specific type of event, like write events, type this command:
sysdig -r sysdig-trace-nano.scap evt.type=write
The output should be similar to:
Output
21340 13:32:14.577121096 0 nano (27590) < write res=1 data=.
21736 13:32:17.378737309 0 nano (27590) > write fd=1 size=23
21737 13:32:17.378748803 0 nano (27590) < write res=23 data=#This is a test file..#
21752 13:32:17.611797048 0 nano (27590) > write fd=1 size=24
21753 13:32:17.611808865 0 nano (27590) < write res=24 data= This is a test file..#
21768 13:32:17.992495582 0 nano (27590) > write fd=1 size=25
21769 13:32:17.992504622 0 nano (27590) < write res=25 data=TThis is a test file..# T
21848 13:32:18.338497906 0 nano (27590) > write fd=1 size=25
21849 13:32:18.338506469 0 nano (27590) < write res=25 data=hThis is a test file..[5G
21864 13:32:18.500692107 0 nano (27590) > write fd=1 size=25
21865 13:32:18.500714395 0 nano (27590) < write res=25 data=iThis is a test file..[6G
21880 13:32:18.529249448 0 nano (27590) > write fd=1 size=25
21881 13:32:18.529258664 0 nano (27590) < write res=25 data=sThis is a test file..[7G
21896 13:32:18.620305802 0 nano (27590) > write fd=1 size=25
Let's look at the contents of the file you saved in the previous section: the sysdig-write-events.scap file. We know that all events saved to the file are write events, so let's view the contents:
sudo sysdig -r sysdig-write-events.scap evt.type=write
This is a partial output. You will see something like this if there was any SSH activity on the server when you captured the events:
Output
42585 19:58:03.040970004 0 gmain (14818) < write res=8 data=........
42650 19:58:04.279052747 0 sshd (22863) > write fd=3(<4t>11.11.11.11:43566->22.22.22.22:ssh) size=28
42651 19:58:04.279128102 0 sshd (22863) < write res=28 data=.8c..jp...P........s.E<...s.
42780 19:58:06.046898181 0 sshd (12392) > write fd=3(<4t>11.11.11.11:51282->22.22.22.22:ssh) size=28
42781 19:58:06.046969936 0 sshd (12392) < write res=28 data=M~......V.....Z...\..o...N..
42974 19:58:09.338168745 0 sshd (22863) > write fd=3(<4t>11.11.11.11:43566->22.22.22.22:ssh) size=28
42975 19:58:09.338221272 0 sshd (22863) < write res=28 data=66..J.._s&U.UL8..A....U.qV.*
43104 19:58:11.101315981 0 sshd (12392) > write fd=3(<4t>11.11.11.11:51282->22.22.22.22:ssh) size=28
43105 19:58:11.101366417 0 sshd (12392) < write res=28 data=d).(...e....l..D.*_e...}..!e
43298 19:58:14.395655322 0 sshd (22863) > write fd=3(<4t>11.11.11.11:43566->22.22.22.22:ssh) size=28
43299 19:58:14.395701578 0 sshd (22863) < write res=28 data=.|.o....\...V...2.$_...{3.3|
43428 19:58:16.160703443 0 sshd (12392) > write fd=3(<4t>11.11.11.11:51282->22.22.22.22:ssh) size=28
43429 19:58:16.160788675 0 sshd (12392) < write res=28 data=..Hf.%.Y.,.s...q...=..(.1De.
43622 19:58:19.451623249 0 sshd (22863) > write fd=3(<4t>11.11.11.11:43566->22.22.22.22:ssh) size=28
43623 19:58:19.451689929 0 sshd (22863) < write res=28 data=.ZT^U.pN....Q.z.!.i-Kp.o.y..
43752 19:58:21.216882561 0 sshd (12392) > write fd=3(<4t>11.11.11.11:51282->22.22.22.22:ssh) size=28
4t>4t>4t>4t>4t>4t>4t>4t>
Notice that all the lines in the preceding output contain 11.11.11.11:51282->22.22.22.22:ssh. Those are events coming from the external IP address of the client, 11.11.11.11 to the IP address of the server, 22.22.22.22 . These events occurred over an SSH connection to the server, so those events are expected. But are there other SSH write events that are not from this known client IP address? It's easy to find out.
There are many comparison operators you can use with Sysdig. The first one you saw is =. Others are !=, >, >=, <, and <=. In the following command, fd.rip filters on remote IP address. We'll use the != comparison operator to look for events that are from IP addresses other than 11.11.11.11:
sysdig -r sysdig-write-events.scap fd.rip!=11.11.11.11
A partial output, which showed that there were write events from IP addresses other than the client IP address, is shown in the following output:
Output
294479 21:47:47.812314954 0 sshd (28766) > read fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) size=1
294480 21:47:47.812315804 0 sshd (28766) < read res=1 data=T
294481 21:47:47.812316247 0 sshd (28766) > read fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) size=1
294482 21:47:47.812317094 0 sshd (28766) < read res=1 data=Y
294483 21:47:47.812317547 0 sshd (28766) > read fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) size=1
294484 21:47:47.812318401 0 sshd (28766) < read res=1 data=.
294485 21:47:47.812318901 0 sshd (28766) > read fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) size=1
294486 21:47:47.812320884 0 sshd (28766) < read res=1 data=.
294487 21:47:47.812349108 0 sshd (28766) > fcntl fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) cmd=4(F_GETFL)
294488 21:47:47.812350355 0 sshd (28766) < fcntl res=2(/dev/null)
294489 21:47:47.812351048 0 sshd (28766) > fcntl fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) cmd=5(F_SETFL)
294490 21:47:47.812351918 0 sshd (28766) < fcntl res=0(/dev/null)
294554 21:47:47.813383844 0 sshd (28767) > write fd=3(<4t>33.33.33.33:49802->22.22.22.22:ssh) size=976
294555 21:47:47.813395154 0 sshd (28767) < write res=976 data=........zt.....L.....}....curve25519-sha256@libssh.org,ecdh-sha2-nistp256,ecdh-s
294691 21:47:48.039025654 0 sshd (28767) > read fd=3(<4t>221.229.172.117:49802->45.55.71.190:ssh) size=8192
4t>4t>4t>4t>4t>4t>4t>4t>
Further investigation also showed that the rogue IP address 33.33.33.33 belonged to a machine in China. That's something to worry about! That's just one example of how you can use Sysdig to keep a watchful eye on traffic hitting your server.
Let's look at using some additional scripts to analyze the event stream.
Using Sysdig Chisels for System Monitoring and Analysis
In Sysdig parlance, chisels are Lua scripts you can use that analyze the Sysdig event stream to perform useful actions. There are close to 50 scripts that ship with every Sysdig installation, and you can view a list of available chisels on your system using this command:
sysdig -cl
Some of the more interesting chisels include:
- netstat: List (and optionally filter) network connections.
- shellshock_detect: Print shellshock attacks
- spy_users: Display interactive user activity.
- listloginshells: List the login shell IDs.
- spy_ip: Show the data exchanged with the given IP address.
- spy_port: Show the data exchanged using the given IP port number.
- spy_file: Echo any read or write made by any process to all files. Optionally, you can provide the name of a file to only intercept reads or writes to that file.
- httptop: Show the top HTTP requests
For a more detailed description of a chisel, including any associated arguments, use the -i flag, followed by the name of the chisel. So, for example, to view more information about the netstat chisel, type:
sysdig -i netstat
Now that you know all you need to know about using that netstat chisel, tap into its power to monitor your system by running:
sudo sysdig -c netstat
The output should be similar to the following:
Output
Proto Server Address Client Address State TID/PID/Program Name
tcp 22.22.22.22:22 11.11.11.11:60422 ESTABLISHED 15567/15567/sshd
tcp 0.0.0.0:22 0.0.0.0:* LISTEN 1613/1613/sshd
If you see ESTABLISHED SSH connections from an IP address other than yours in the Client Address column, that should be a red flag, and you should probe deeper.
A far more interesting chisel is spy_users, which lets you view interactive user activity on the system.
Exit this command:
sudo sysdig -c spy_users
Then, open a second terminal and connect to your server. Execute some commands in that second terminal, then return to your terminal running sysdig. The commands you typed in the first terminal will be echoed on the terminal that you executed the sysdig -c spy_users command on.
Next, let's explore Csysdig, a graphical tool.
Using Csysdig for System Monitoring and Analysis
Csysdig is the other utility that comes with Sysdig. It has an interactive user interface that offers the same features available on the command line with sysdig. It's like top, htop and strace, but more feature-rich.
Like the sysdig command, the csysdig command can perform live monitoring and can capture events to a file for later analysis. But csysdig gives you a more useful real time view of system data refreshed every two seconds. To see an example of that, type the following command:
sudo csysdig
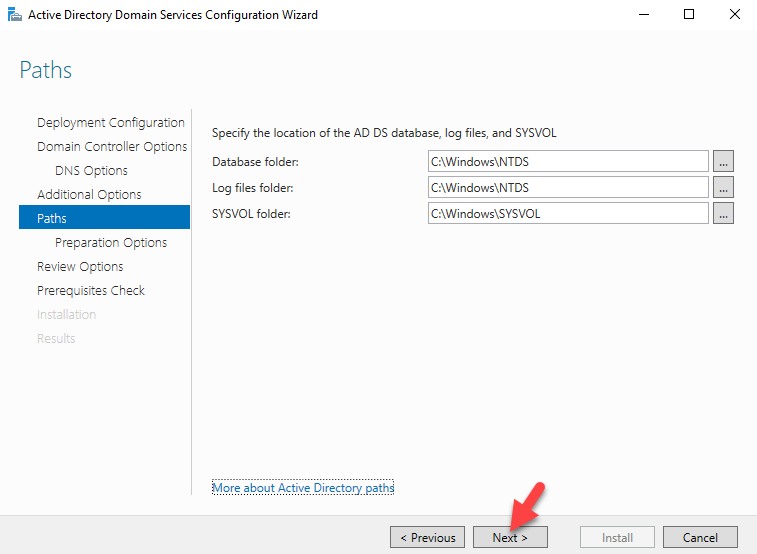
That will open an interface like the one in the following figure, which shows event data generated by all users and applications on the monitored host.
![]()
At the bottom of the interface are several buttons you can use to access the different aspects of the program. Most notable is the Views button, which is akin to categories of metrics collected by csysdig. There are 29 views available out of the box, including Processes, System Calls, Threads, Containers, Processes CPU, Page Faults, Files, and Directories.
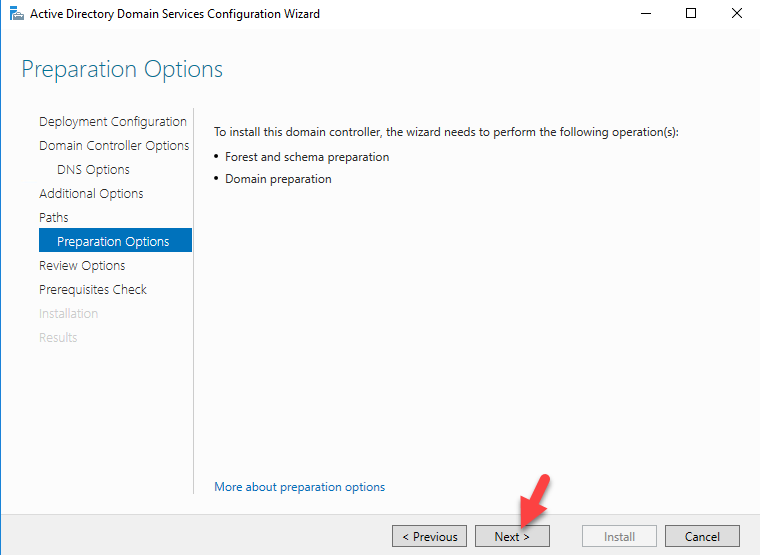
When you start csysdig without arguments, you'll see live events from the Processes view. By clicking on the Views button, or pressing the F2 key, you'll see the list of available views, including a description of the columns. You may also view a description of the columns by pressing the F7 key or by clicking the Legend button. And a summary man page of the application itself (csysdig) is accessible by pressing the F1 key or clicking on the Help button.
The following image shows a listing of the application's Views interface.
Though you can run csysdig without any options and arguments, the command's syntax, as with sysdig's, usually takes this form:
sudo csysdig [option]... [filter]The most common option is -d, which is used to modify the delay between updates in milliseconds. For example, to view csysdig output updated every 10 seconds, instead of the default of 2 seconds, type:
sudo csysdig -d 10000You can exclude the user and group information from views with the -E option:
sudo csysdig -EThis can make csysdig start up faster, but the speed gain is negligible in most situations.
To instruct csysdig to stop capturing after a certain number of events, use the -n option. The application will exit after that number has been reached. The number of captured events has to be in the five figures; otherwise you won't even see the csysdig UI:
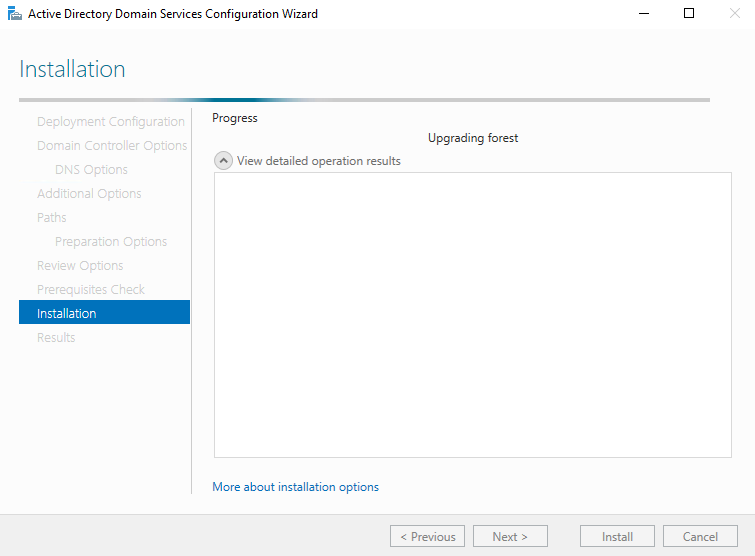
sudo csysdig -n 100000To analyze a trace file, pass csysdig the -r option, like so:
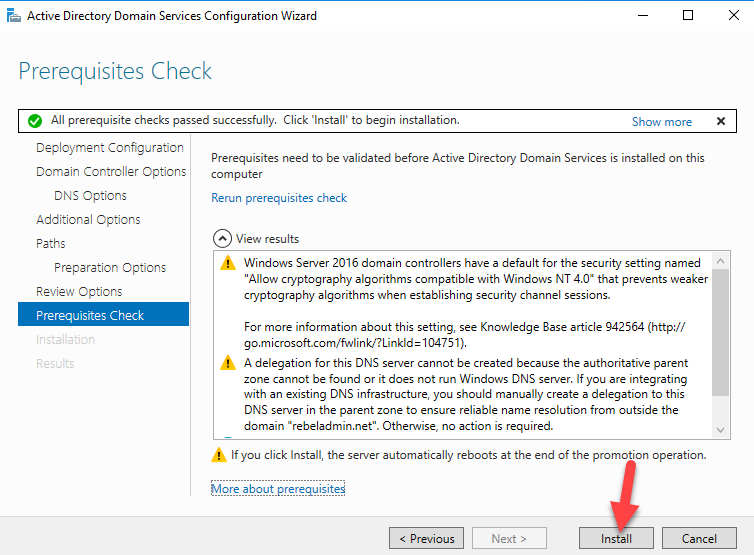
sudo csysdig -r sysdig-trace-file.scapYou can use the same filters you used with sysdig to restrict csysdig's output. So, for example, rather than viewing event data generated by all users on the system, you can filter the output by users by launching csysdig with the following command, which will show event data only generated by the root user:
sudo csysdig user.name=rootThe output should be similar to the one shown in the following image, although the output will reflect what's running on your server:
To view the output for an executable generating an event, pass the filter the name of the binary without the path. The following example will show all events generated by the nano command. In other words, it will show all open files where the text editor is nano:
sudo csysdig proc.name=nano
There are several dozen filters available, which you can view with the following command:
sudo csysdig -l
You'll notice that that was the same option you used to view the filters available with sysdig command. So sysdig and csysdig are just about the same. The main difference is that csysdig comes with a mouse-friendly interactive UI. To exit csysdig at any time, press the Q key on your keyboard.
Conclusion
Sysdig helps you monitor and troubleshoot your server. It will give you a deep insight into all the system activity on a monitored host, including those generated by application containers. More information is available on the project's
home page.