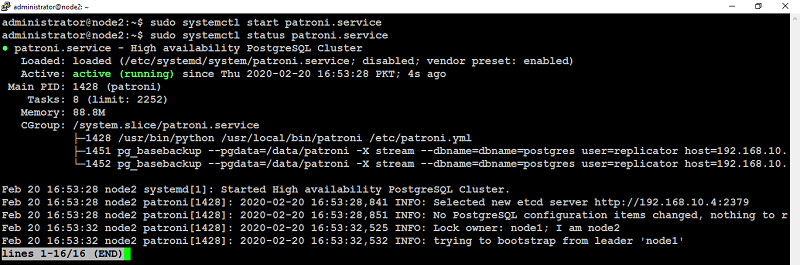
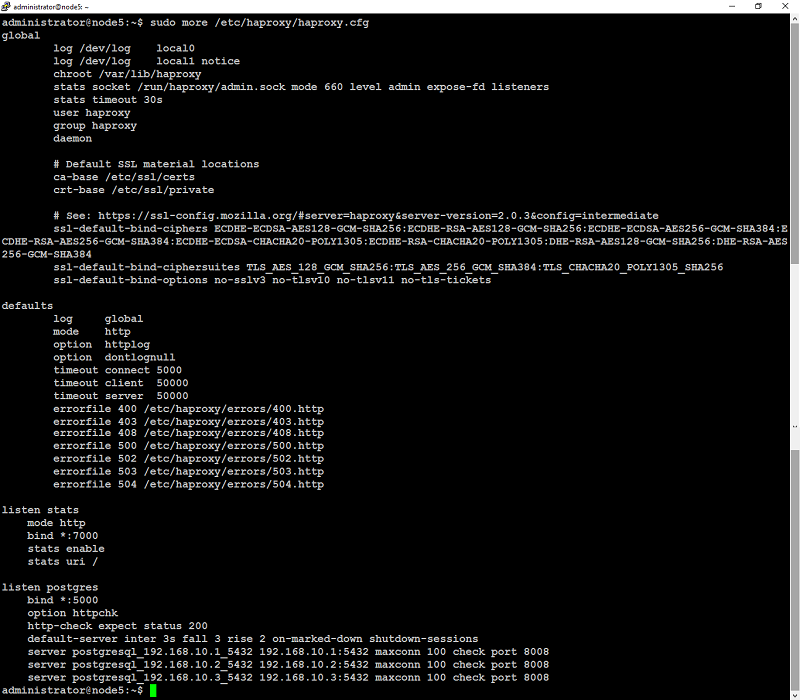
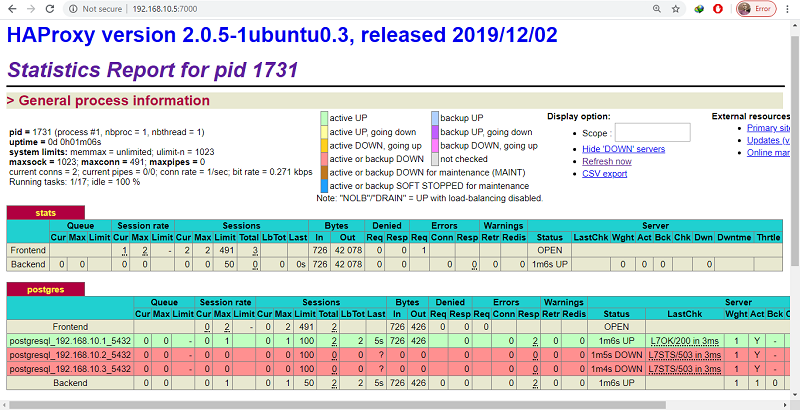
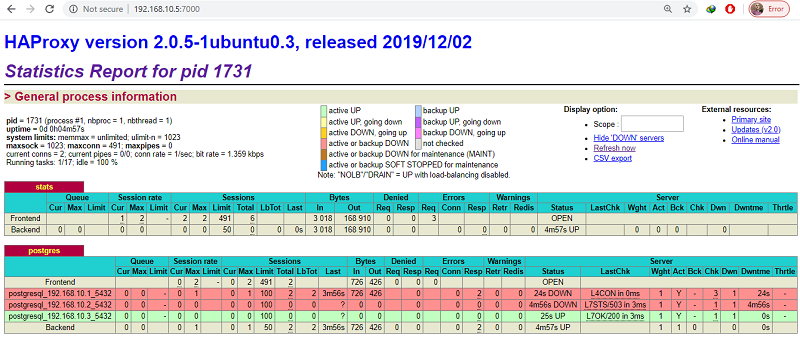
This tutorial will walk you through the steps to set up a highly available fault-tolerant MongoDB sharded cluster using a shared storage for your production use. If you are not intend to use shared storage, follow this
tutorial.
A MongoDB sharded cluster consists of the following three components:
Shard that can be deployed as a replica set.
Config store metadata and configuration settings for the cluster.
Mongos acts as a query router, providing an interface between client applications and the sharded cluster.
The following illustration describes the interaction of components within a sharded cluster, and you can see, there is no single point of failure in this highly available setup.
Prerequisites
To follow this tutorial along, you will need at least 11 (physical or virtual) machines installed with Ubuntu or Debian having sudo non-root user privileges. Make sure you have completed basic network settings including hostname, timezone, and IP addresses on each of your servers.
We will use these 12 machines with the information (as described) for our sharded cluster throughout this tutorial. Make sure you substitute, hostname, ip address, domain and red highlighted text with yours wherever applicable.
The NFS server that will be used as remote shared storage for this guide is already in place. You can use any storage of your choice whatever suits your environment.
Note: This guide is specifically written for Ubuntu 18.04, 19.04, 19.10, 20.04 and Debian 9, 10.
STEP1 - Create SSH Key-Pair
We will generate an ssh key-pair to set up passwordless authentication between the hosts in the cluster.
Log in to (
cfg1.example.pk), and generate an ssh key-pair with below command:
ssh-keygen
This will return you the following prompts, press enter to select default location:
Generating public/private rsa key pair.
Enter file in which to save the key (/home/administrator/.ssh/id_rsa):
Again press enter to leave the passphrase fields blank:
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
You will see similar to the following output, confirms that the generating ssh key-pair succeeded under your user's home directory
Your identification has been saved in /home/administrator/.ssh/id_rsa.
Your public key has been saved in /home/administrator/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:DWWeuoSoQgHJnYkbrs8QoFs8oMjP0Sv8/3ehuN17MPE administrator@cfg1.example.pk
The key's randomart image is:
+---[RSA 2048]----+
|o.o o o |
|=+ + + . |
|B+o . . o |
|=+=. o . + . |
|.=+.o o S . o |
|= * . . . + E |
|.+. o . . . + |
| .o . ..o.. . |
| ...oo..oo |
+----[SHA256]-----+
Type below to create an
authorized_keys file:
ssh-copy-id -i .ssh/id_rsa.pub localhost
Copy ~/.ssh directory with all its contents from cfg1.example.pk to each of your servers like below:
scp -r /home/administrator/.ssh/ cfg2.example.pk:~/
scp -r /home/administrator/.ssh/ cfg3.example.pk:~/
scp -r /home/administrator/.ssh/ shrd1.example.pk:~/
scp -r /home/administrator/.ssh/ shrd2.example.pk:~/
scp -r /home/administrator/.ssh/ shrd3.example.pk:~/
scp -r /home/administrator/.ssh/ shrd4.example.pk:~/
scp -r /home/administrator/.ssh/ shrd5.example.pk:~/
scp -r /home/administrator/.ssh/ shrd6.example.pk:~/
scp -r /home/administrator/.ssh/ qrt1.example.pk:~/
scp -r /home/administrator/.ssh/ qrt2.example.pk:~/
If everything set up correctly as demonstrated above, you can access any of your servers via ssh, and it won't prompt you for the password anymore.
STEP2 - Update Hosts File
If you are running a DNS server, you can create HOST-A records to resolve names against servers' IP addresses. For this guide, we will use /etc/hosts file to map each server's name against its IP address:
Log in to (
cfg1.example.pk), edit
/etc/hosts file:
sudo nano /etc/hosts
add each of your servers's name and IP addresses in the
hosts file like below:
# Config Server Replica Set
192.168.10.1 cfg1.example.pk
192.168.10.2 cfg2.example.pk
192.168.10.3 cfg3.example.pk
# Shard Server Replica Set (rs0)
192.168.10.4 shrd1.example.pk
192.168.10.5 shrd2.example.pk
192.168.10.6 shrd3.example.pk
# Shard Server Replica Set (rs1)
192.168.10.7 shrd4.example.pk
192.168.10.8 shrd5.example.pk
192.168.10.9 shrd6.example.pk
# Mongos (Query Router)
192.168.10.10 qrt1.example.pk
192.168.10.11 qrt2.example.pk
# NFS Shared Storage
192.168.10.12 rstg.example.pk
Save and close the file when you are finished.
Repeat the same on each of your remaining servers before proceeding to the next step.
STEP3 - Add MongoDB Source
Ubuntu default apt source list doesn't provide the latest release of mongodb database, hence we need to add mongodb official packages source on each server to install the latest stable version.
On (
cfg1.example.pk), add MongoDB official repository with below command:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
From cfg1.example.pk, add mongodb source on each of your remaining servers via ssh as we have already set up passwordless authentication.
ssh cfg2.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh cfg3.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh shrd1.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh shrd2.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh shrd3.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh shrd4.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh shrd5.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh shrd6.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
ssh qrt1.example.pk
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4b7c549a058f8b6b
echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
exit
STEP4 - Installing MongoDB
On (
cfg1.example.pk) install mongodb latest stable release like below:
sudo apt update
sudo apt -y install mongodb-org
When installation complete on your cfg1.example.pk, install mongodb on each of your remaining servers using ssh like below:
ssh cfg2.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh cfg3.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh shrd1.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh shrd2.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh shrd3.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh shrd4.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh shrd5.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh shrd6.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh qrt1.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
ssh qrt2.example.pk
sudo apt update
sudo apt -y install mongodb-org
exit
With this, you have completed mongodb installation on each of your servers.
STEP5 - Install NFS Client
To mount an NFS share, we need to install nfs client. You can skip this step if you are not using nfs shared storage.
On (
cfg1.example.pk) , install and run nfs client like below:
sudo apt -y install nfs-common
sudo systemctl start rpcbind nfs-client.target
sudo systemctl enable rpcbind nfs-client.target
Repeat the same nfs client installation step on each of your remaining servers before proceeding to next.
STEP6 - Mount NFS Share
On (
cfg1.exampke.pk), type below command to mount nfs share.
sudo mkdir /nfs_share/
sudo mount rstg.example.pk:/u01/mongodb_shared_storage /nfs_share
sudo mkdir /nfs_share/mongodb
Create data directory for each server under
nfs_share like below:
sudo mkdir /nfs_share/mongodb/cfg1
sudo mkdir /nfs_share/mongodb/cfg2
sudo mkdir /nfs_share/mongodb/cfg3
sudo mkdir /nfs_share/mongodb/shrd1
sudo mkdir /nfs_share/mongodb/shrd2
sudo mkdir /nfs_share/mongodb/shrd3
sudo mkdir /nfs_share/mongodb/shrd4
sudo mkdir /nfs_share/mongodb/shrd5
sudo mkdir /nfs_share/mongodb/shrd6
sudo mkdir /nfs_share/mongodb/qrt1
sudo mkdir /nfs_share/mongodb/qrt2
Set appropriate permission on
nfs_share like below:
sudo chown -R mongodb:mongodb /nfs_share/
sudo chmod -R 755 /nfs_share/
Type below command on each of your remaining servers to mount nfs share:
sudo mkdir /nfs_share/
sudo chown -R mongodb:mongodb /nfs_share/
sudo chmod -R 755 /nfs_share/
sudo mount rstg.example.pk:/u01/mongodb_shared_storage /nfs_share
STEP7 - Configure MongoDB
At this stage, we need to make a change under
mongod.conf file to tell mongodb where to store data.
Login to your
cfg1.example.pk and edit
/etc/mongod.conf like below:
sudo nano /etc/mongod.conf
Update
dbPath value with your shared storage like below:
dbPath: /nfs_share/mongodb/cfg1
Save and close file when you are finished
Start mongod service and make it persistent on reboot with below command:
sudo systemctl start mongod
sudo systemctl enable mongod
Confirm that mongod service is active and running with below command:
sudo systemctl status mongod
You can see in the below output that mongod is active and running.
● mongod.service - MongoDB Database Server
Loaded: loaded (/lib/systemd/system/mongod.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2020-03-19 09:37:32 PKT; 4min 16s ago
Docs: https://docs.mongodb.org/manual
Main PID: 6024 (mongod)
CGroup: /system.slice/mongod.service
└─6024 /usr/bin/mongod --config /etc/mongod.conf
Make sure you repeat the same on each of your remaining servers except (
qrt1, qrt2) before proceeding to next step.
STEP8 - Create a Administrative User
To Administer and manage mongodb sharded cluster, we need to create an administrative user with root privileges.
On (
cfg1.example.pk), type below command to access mongo shell:
mongo
You will see mongo shell prompt like below:
MongoDB shell version v4.2.3
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("8abb0c14-e2cf-4947-855b-d339279b52c9") }
MongoDB server version: 4.2.3
Welcome to the MongoDB shell.
>
On mongo shell, type below to switch to the default admin database:
use admin
Type below on mongo shell to create a user called "administrator", make sure you replace “password” with a strong password of your choice:
db.createUser({user: "administrator", pwd: "password", roles:[{role: "root", db: "admin"}]})This will return similar to the following output:
Successfully added user: {
"user" : "administrator",
"roles" : [
{
"role" : "root",
"db" : "admin"
}
]
}Type below to exit from mongo shell:
quit()
You will also need to create same user on (
shrd1.example.pk)
ssh shrd1.example.pk
sudo systemctl start mongod;sudo systemctl enable mongod
mongo
use admin
db.createUser({user: "administrator", pwd: "password", roles:[{role: "root", db: "admin"}]})
quit()
exit
and on (
shrd4.example.pk) as well:
ssh shrd4.example.pk
sudo systemctl start mongod;sudo systemctl enable mongod
mongo
use admin
db.createUser({user: "administrator", pwd: "password", roles:[{role: "root", db: "admin"}]})
quit()
exit
When you are finished creating user on (
cfg1, shrd1, shrd4), proceed to next step.
STEP9 - Set Up MongoDB Authentication
We will generate a key file that will be used to secure authentication between the members of replica set. While in this guide we’ll be using a key file generated with
openssl, MongoDB recommends using an
X.509 certificate to secure connections between production systems.
On (
cfg1.example.pk), type below command to generate a key file and set appropriate permission:
openssl rand -base64 756 > ~/mongodb_key.pem
sudo cp ~/mongodb_key.pem /nfs_share/mongodb/
sudo chown -R mongodb:mongodb /nfs_share/mongodb/mongodb_key.pem
sudo chmod -R 400 /nfs_share/mongodb/mongodb_key.pem
As you can see, we have stored key file under nfs_share directory which means each server can read this file from the same location with identical permission. In case of local storage (/var/lib/mongodb) for example, you have to copy key file under the same location and set identical permission to each of your servers.
STEP10 - Set Up Config Servers Replica Set
We will make few changes in
mongod.conf file on (
cfg1, cfg2, cfg3) servers:
Log in to your (
cfg1.example.pk), edit
mongod.conf like below:
sudo nano /etc/mongod.conf
Add, update following values, make sure you replace
port value with
27019 and
bindIp value with your server's name:
port: 27019
bindIp: cfg1.example.pk
security:
keyFile: /nfs_share/mongodb/mongodb_key.pem
replication:
replSetName: configReplSet
sharding:
clusterRole: configsvr
Save and close when you are finished.
Restart mongod service to take changes into effect:
sudo systemctl restart mongod
sudo systemctl status mongod
Make sure you repeat the same on each of your remaining config servers (
cfg2.example.pk, cfg3.example.pk), before proceeding to next step.
STEP11 - Initiate the Config Replica Set.
Log in to your (
cfg1.example.pk), connect to the MongoDB shell over port
27019 with the administrator user like below:
mongo --host cfg1.example.pk --port 27019 -u administrator --authenticationDatabase admin
This will prompt you for password:
MongoDB shell version v4.2.3
Enter password:
From the mongo shell, initiate the config server's replica set like below:
rs.initiate({ _id: "configReplSet", configsvr: true, members: [{ _id : 0, host : "cfg1.example.pk:27019"},{ _id : 1, host : "cfg2.example.pk:27019"},{ _id : 2, host : "cfg3.example.pk:27019"}]})You will see a message like below indicating that operation succeeded:
{
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1584600261, 1),
"electionId" : ObjectId("000000000000000000000000")
},
"lastCommittedOpTime" : Timestamp(0, 0)
}
configReplSet:SECONDARY>
Notice that the MongoDB shell prompt has also changed to
configReplSet:SECONDARY> or
configReplSet:PRIMARY>.
To make sure that each config server has been added to the replica set, type below on mongo shell:
rs.config()
If the replica set has been configured properly, you’ll see output similar to the following:
{
"_id" : "configReplSet",
"version" : 1,
"configsvr" : true,
"protocolVersion" : NumberLong(1),
"writeConcernMajorityJournalDefault" : true,
"members" : [
{
"_id" : 0,
"host" : "cfg1.example.pk:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "cfg2.example.pk:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "cfg3.example.pk:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("5e7314c4ba14c5d2412a1949")
}
}
For maximum replica set configuration information, type below:
rs.status()
You’ll see output similar to the following:
{
"set" : "configReplSet",
"date" : ISODate("2020-03-19T06:47:14.266Z"),
"myState" : 1,
"term" : NumberLong(1),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"configsvr" : true,
"heartbeatIntervalMillis" : NumberLong(2000),
"majorityVoteCount" : 2,
"writeMajorityCount" : 2,
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1584600433, 1),
"t" : NumberLong(1)
},
"lastCommittedWallTime" : ISODate("2020-03-19T06:47:13.490Z"),
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1584600433, 1),
"t" : NumberLong(1)
},
"readConcernMajorityWallTime" : ISODate("2020-03-19T06:47:13.490Z"),
"appliedOpTime" : {
"ts" : Timestamp(1584600433, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1584600433, 1),
"t" : NumberLong(1)
},
"lastAppliedWallTime" : ISODate("2020-03-19T06:47:13.490Z"),
"lastDurableWallTime" : ISODate("2020-03-19T06:47:13.490Z")
},
"lastStableRecoveryTimestamp" : Timestamp(1584600391, 1),
"lastStableCheckpointTimestamp" : Timestamp(1584600391, 1),
"electionCandidateMetrics" : {
"lastElectionReason" : "electionTimeout",
"lastElectionDate" : ISODate("2020-03-19T06:44:32.291Z"),
"electionTerm" : NumberLong(1),
"lastCommittedOpTimeAtElection" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"lastSeenOpTimeAtElection" : {
"ts" : Timestamp(1584600261, 1),
"t" : NumberLong(-1)
},
"numVotesNeeded" : 2,
"priorityAtElection" : 1,
"electionTimeoutMillis" : NumberLong(10000),
"numCatchUpOps" : NumberLong(0),
"newTermStartDate" : ISODate("2020-03-19T06:44:33.110Z"),
"wMajorityWriteAvailabilityDate" : ISODate("2020-03-19T06:44:34.008Z")
},
"members" : [
{
"_id" : 0,
"name" : "cfg1.example.pk:27019",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1013,
"optime" : {
"ts" : Timestamp(1584600433, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-03-19T06:47:13Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"electionTime" : Timestamp(1584600272, 1),
"electionDate" : ISODate("2020-03-19T06:44:32Z"),
"configVersion" : 1,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "cfg2.example.pk:27019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 173,
"optime" : {
"ts" : Timestamp(1584600421, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1584600421, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-03-19T06:47:01Z"),
"optimeDurableDate" : ISODate("2020-03-19T06:47:01Z"),
"lastHeartbeat" : ISODate("2020-03-19T06:47:12.377Z"),
"lastHeartbeatRecv" : ISODate("2020-03-19T06:47:14.013Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "cfg1.example.pk:27019",
"syncSourceHost" : "cfg1.example.pk:27019",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "cfg3.example.pk:27019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 173,
"optime" : {
"ts" : Timestamp(1584600421, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1584600421, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-03-19T06:47:01Z"),
"optimeDurableDate" : ISODate("2020-03-19T06:47:01Z"),
"lastHeartbeat" : ISODate("2020-03-19T06:47:12.377Z"),
"lastHeartbeatRecv" : ISODate("2020-03-19T06:47:14.020Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "",
"syncingTo" : "cfg1.example.pk:27019",
"syncSourceHost" : "cfg1.example.pk:27019",
"syncSourceId" : 0,
"infoMessage" : "",
"configVersion" : 1
}
],
"ok" : 1,
"$gleStats" : {
"lastOpTime" : Timestamp(1584600261, 1),
"electionId" : ObjectId("7fffffff0000000000000001")
},
"lastCommittedOpTime" : Timestamp(1584600433, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1584600433, 1),
"signature" : {
"hash" : BinData(0,"5S/ou6ONJAUK+J4roPWAKmOf2nk="),
"keyId" : NumberLong("6805806349767671838")
}
},
"operationTime" : Timestamp(1584600433, 1)
}
Now exit from mongo shell with below command:
quit()
STEP12 - Create the Shard Replica Set (rs0)
We will configure shard replica set (
rs0) on (
shrd1, shrd2, shrd3) servers.
Log in to (
shrd1.example.pk), edit
/etc/mongod.conf file like below:
sudo nano /etc/mongod.conf
Add, update the following values, make sure you replace
port value with
27018 and
bindIp value with your server's name:
net:
port: 27018
bindIp: shrd1.example.pk
security:
keyFile: /var/lib/mongodb/mongodb_key.pem
replication:
replSetName: rs0
sharding:
clusterRole: shardsvr
Save and close when you are finished.
Restart mongod service to take changes into effect:
sudo systemctl restart mongod
sudo systemctl status monogod
Make sure you repeat the same on (
shrd2, shrd3) server before proceeding to next step.
STEP13 - Initiate the shard replica set (rs0)
Log in to (
shrd1.example.pk), connect to mongo shell on port
27018 with administrator user like below:
mongo --host shrd1.example.pk --port 27018 -u administrator --authenticationDatabase admin
Type below on mongo shell to initiate shard replica set (
rs0):
rs.initiate({ _id : "rs0", members:[{ _id : 0, host : "shrd1.example.pk:27018" },{ _id : 1, host : "shrd2.example.pk:27018" },{ _id : 2, host : "shrd3.example.pk:27018" }]})This will return { "ok" : 1 } indicating that shard replica set
rs0 initiated successfully.
Now exit from the mongo shell with below command:
quit()
STEP14 - Create the Shard Replica Set (rs1)
We will configure shard replica set
(rs1) on (
shrd4, shrd5, shrd6) servers.
Log in to (
shrd4.example.pk), edit
/etc/mongod.conf file:
sudo nano /etc/mongod.conf
Add, update the following values, make sure you replace port value with
27018 and
bindIp with your server's name:
net:
port: 27018
bindIp: shrd4.example.pk
security:
keyFile: /nfs_share/mongodb/mongodb_key.pem
replication:
replSetName: rs1
sharding:
clusterRole: shardsvr
Save and close file when you are finished.
Restart mongod service with below command to take changes into effect:
sudo systemctl restart mongod
sudo systemctl status mongod
Repeat the same on (
shrd5, shrd6) before proceeding to next step.
STEP15 - Initiate the shard replica set (rs1)
Log in to (
shrd1.example.pk), connect to mongo shell on port
27018 with administrative authentication like below:
mongo --host shrd4.example.pk --port 27018 -u administrator --authenticationDatabase admin
Type below on mongo shell to initiate shard replica set (rs1):
rs.initiate({ _id : "rs1", members:[{ _id : 0, host : "shrd4.example.pk:27018" },{ _id : 1, host : "shrd5.example.pk:27018" },{ _id : 2, host : "shrd6.example.pk:27018" }]})This will return { "ok" : 1 } indicating that shard replica set rs0 is initiated successfully.
Now exit from the mongo shell with below command:
quit()
STEP16 - Configure Mongos (Query Router)
We'll create a mongos service that needs to obtain data locks, so be sure mongod is stopped before proceeding:
Log in to (
qrt1.example.pk), and deactivate
mongod service with below command:
sudo systemctl stop mongod
sudo systemctl disable mongod
Confirm that mongod service is stopped with below command:
sudo systemctl status mongod
The output confirm that mongod is stopped:
● mongod.service - MongoDB Database Server
Loaded: loaded (/lib/systemd/system/mongod.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: https://docs.mongodb.org/manual
Mar 19 13:35:48 qrt1.example.pk systemd[1]: Stopped MongoDB Database Server.
On (
qrt1.example.pk), create
mongos.conf file file like below:
sudo nano /etc/mongos.conf
Add the following configuration directives
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongos.log
net:
port: 27017
bindIp: qrt1.example.pk
security:
keyFile: /nfs_share/mongodb/mongodb_key.pem
sharding:
configDB: configReplSet/cfg1.example.pk:27019,cfg2.example.pk:27019,cfg3.example.pk:27019
Save and close file.
Next, create a systemd service unit file for mongos like below:
sudo nano /lib/systemd/system/mongos.service
Add the following parameters:
[Unit]
Description=Mongo Cluster Router
After=network.target
[Service]
User=mongodb
Group=mongodb
ExecStart=/usr/bin/mongos --config /etc/mongos.conf
LimitFSIZE=infinity
LimitCPU=infinity
LimitAS=infinity
LimitNOFILE=64000
LimitNPROC=64000
TasksMax=infinity
TasksAccounting=false
[Install]
WantedBy=multi-user.target
Save and close.
Start mongos service with below command to activate query router.
sudo systemctl start mongos
sudo systemctl enable mongos
Confirm that mongos is active and running with below command:
sudo systemctl status mongos
You will see mongos status like below.
● mongos.service - Mongo Cluster Router
Loaded: loaded (/lib/systemd/system/mongos.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2020-03-19 13:59:25 PKT; 33s ago
Main PID: 26985 (mongos)
CGroup: /system.slice/mongos.service
└─26985 /usr/bin/mongos --config /etc/mongos.conf
Mar 19 13:59:25 qrt1.example.pk systemd[1]: Started Mongo Cluster Router.
Next, log in to
qrt2.example.pk and stop mongod like below:
sudo systemctl stop mongod
sudo systemctl disable mongod
Create
mongos.conf file:
sudo nano /etc/mongos.conf
Add the same configuration directives, like we did on
qrt1.example.pk, replace
bindIp value with
qrt2.example.pk:
systemLog:
destination: file
logAppend: true
path: /var/log/mongodb/mongos.log
net:
port: 27017
bindIp: qrt2.example.pk
security:
keyFile: /nfs_share/mongodb/mongodb_key.pem
sharding:
configDB: configReplSet/cfg1.example.pk:27019,cfg2.example.pk:27019,cfg3.example.pk:27019
Save and close when you are finished.
Next, create a systemd service unit file:
sudo nano /lib/systemd/system/mongos.service
Add the following same parameters we did on
qrt1.example.pk[Unit]
Description=Mongo Cluster Router
After=network.target
[Service]
User=mongodb
Group=mongodb
ExecStart=/usr/bin/mongos --config /etc/mongos.conf
LimitFSIZE=infinity
LimitCPU=infinity
LimitAS=infinity
LimitNOFILE=64000
LimitNPROC=64000
TasksMax=infinity
TasksAccounting=false
[Install]
WantedBy=multi-user.target
Save and close.
Start mongos service with below command to activate query router.
sudo systemctl start mongos
sudo systemctl enable mongos
Confirm that mongos is active and running with below command:
sudo systemctl status mongos
You will see mongos status like below.
● mongos.service - Mongo Cluster Router
Loaded: loaded (/lib/systemd/system/mongos.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2020-03-19 14:04:35 PKT; 40min ago
Main PID: 27137 (mongos)
CGroup: /system.slice/mongos.service
└─27137 /usr/bin/mongos --config /etc/mongos.conf
Mar 19 14:04:35 qrt2.example.pk systemd[1]: Started Mongo Cluster Router.
Add Shards to the Cluster
On (
qrt1.example.pk), connect to mongo shell on port
27017 with administrative authentication like below:
mongo --host qrt1.example.pk --port 27017 -u administrator --authenticationDatabase admin
On mongo shell, type below to add shard replica set (
rs0) in the cluster:
sh.addShard( "rs0/shrd1.example.pk:27018,shrd2.example.pk:27018,shrd2.example.pk:27018")
You will see the similar output indicating that shard replica set
rs0 added successfully.
Type below to add shard replica set (
rs1) in the cluster:
sh.addShard( "rs1/shrd4.example.pk:27018,shrd5.example.pk:27018,shrd6.example.pk:27018")
You will see the similar output indicating that shard replica set
rs1 added successfully.
At this stage, your fault-tolerant sharded cluster is active and running.
STEP17 - Enable Sharding
The last step is to enable sharding for database. This process takes place in stages due to the organization of data in MongoDB. Before you enable sharding, you’ll need to decide on a sharding strategy.
The two most common sharding strategies are:
Range-based sharding divides your data based on specific ranges of values in the shard key.
Hash-based sharding distributes data by using a hash function on your shard key for a more even distribution of data among the shards.
This is not a comprehensive explanation for choosing a sharding strategy. You may wish to consult with official resource of
MongoDB’s documentation on sharding strategy.
For this guide, we’ve decided to use a hash-based sharding strategy, enabling sharding at the collections level. This allows the documents within a collection to be distributed among your shards.
Log in to (
qrt2.example.pk), access the mongos shell:
mongo --host qrt2.example.pk --port 27017 -u administrator --authenticationDatabase admin
From the mongos shell, type below to create a test database called
testDBuse testDB
Create a new collection called
testCollection and hash its
_id key. The
_id key is already created by default as a basic index for new documents:
db.testCollection.ensureIndex( { _id : "hashed" } )You will see the output similar to the following
Type below to enable sharding for newly created database:
sh.enableSharding("testDB")
sh.shardCollection( "testDB.testCollection", { "_id" : "hashed" } )You will see output similar to the following
This enables sharding across any shards that you added to your cluster.
To verify that the sharding was successfully enabled, type below to switch to the config database:
use config
Run below method:
db.databases.find()
If sharding was enabled properly, you will see useful information similar to like below:
Once you enable sharding for a database, MongoDB assigns a primary shard for that database where MongoDB stores all data in that database.
STEP18 - Test MongoDB Sharded Cluster
To ensure your data is being distributed evenly in the database, follow these steps to generate some dummy data in testDB and see how it is divided among the shards.
Connect to the mongos shell on any of your query routers:
mongo --host qrt1.example.pk --port 27017 -u administrator -p --authenticationDatabase admin
Switch to your newly created database (
testDB) for example:
use testDB
Type the following code in the mongo shell to generate 10000 simple dummy documents and insert them into
testCollection:
for (var i = 1; i <= 10000; i++) db.testCollection.insert( { x : i } )Run following code to check your dummy data distribution:
db.testCollection.getShardDistribution()
This will return information similar to the following:
The sections beginning with Shard give information about each shard in your cluster. Since we only added 2 shards with three members each, there are only two sections, but if you add more shards to the cluster, they’ll show up here as well.
The Totals section provides information about the collection as a whole, including its distribution among the shards. Notice that distribution is not perfectly equal. The hash function does not guarantee absolutely even distribution, but with a carefully chosen shard key it will usually be fairly close.
When you’re finished, we recommend you to delete the
testDB (because it has no use) with below command:
use testDB
db.dropDatabase()
Wrapping up
Now that you have successfully deployed a highly available fault-tolerant sharded cluster ready to use for your production environment, we recommended you to configure firewall to limit ports 27018 and 27019 to only accept traffic between hosts within your cluster.
You'll always make connection to the database in the sharded cluster via query routers.