This tutorial will walk you through the steps to set up a highly available PostgreSQL cluster using Patroni and HAProxy on CentOS/RHEL 8.
Prerequisites
To follow this tutorial, you will need 5 (physical or virtual) machines with CentOS or RHEL 8 server with minimal installed, having sudo non-root user privileges. We have already prepared following 5 machines with CentOS release 8.1.1911 for this guide. However, if you wish you can add up more machines in your cluster environment.
| HOSTNAME | IP ADDRESS | PURPOSE |
| node1 | 192.168.10.1 | Postgresql, Patroni |
| node2 | 192.168.10.2 | Postgresql, Patroni |
| node3 | 192.168.10.3 | Postgresql, Patroni |
| node4 | 192.168.10.4 | etcd |
| node5 | 192.168.10.5 | HAProxy |
If you wish, you can watch the below quick video tutorial to set up your postgres cluster environment:
If you are not comfortable with the video tutorial, please follow the below step by step instruction:
Adding EPEL Repository
It is always recommended to install extra packages for enterprise Linux repository before installing any other packages on your server.
Adding PostgreSQL Repository
PostgreSQL version 12 is not available in CentOS/RHEL 8 default repository, therefore we need install official repository of postgres with below command:
Installing PostgreSQL
We are installing PostgreSQL version 12 for this guide. If you wish, you can install any other version of your choice:
Installing Patroni
Patroni is an open-source python package that manages postgres configuration. It can be configured to handle tasks like replication, backups and restorations.
Configuring Patroni
Patroni can be configured using a YAML file which is by default located under /opt/app/patroni/etc/ with appropriate permission.
Now you need to edit postgresql.yml file on each node (node1, node2, node3) with any of your preferred editor i.e. vi, vim, nano etc:
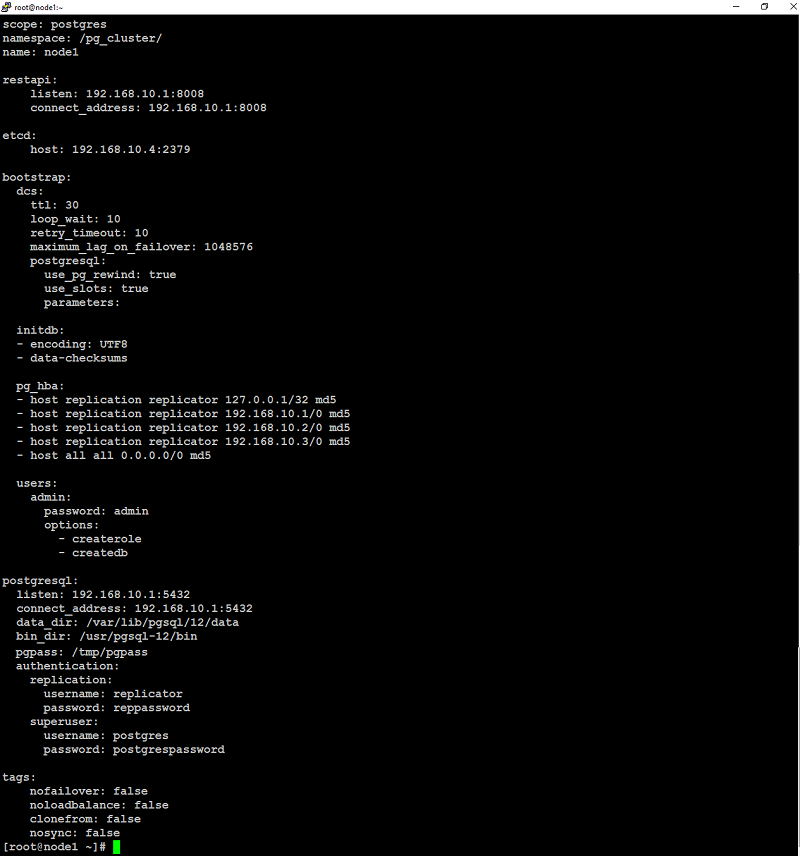
Remove everything from this file and add below configuration parameters:Change name to something unique, and change listen and connect_address (under postgresql and restapi) to the appropriate values on each node (node1, node2, node3 in our case).
For reference, you can see the below screenshots of /opt/app/patroni/etc/postgresql.yml from node1 in our setup:
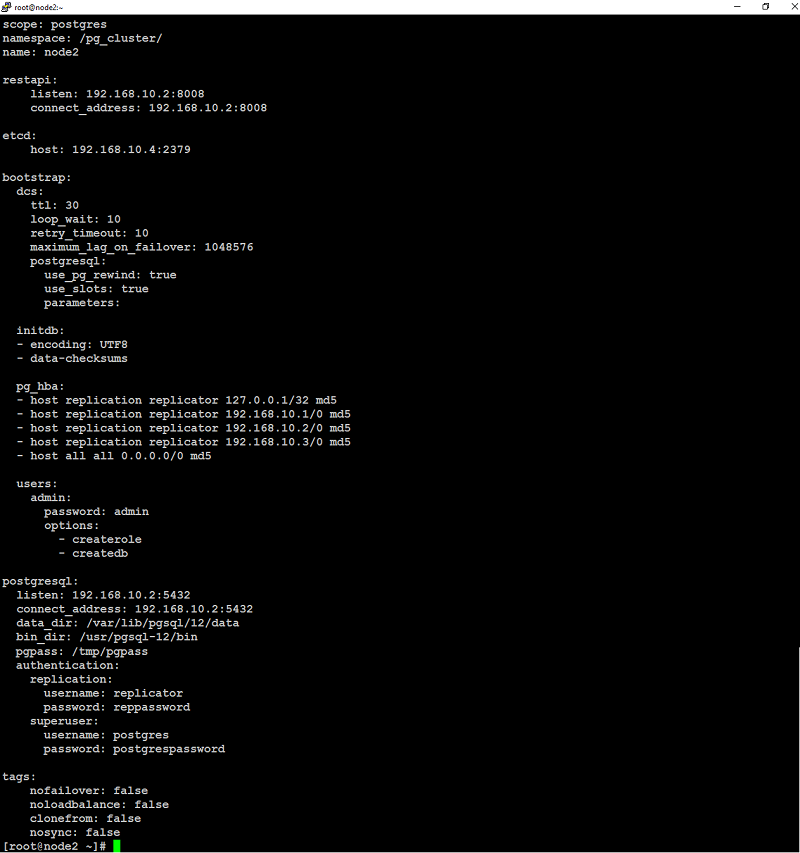
below is from node2:
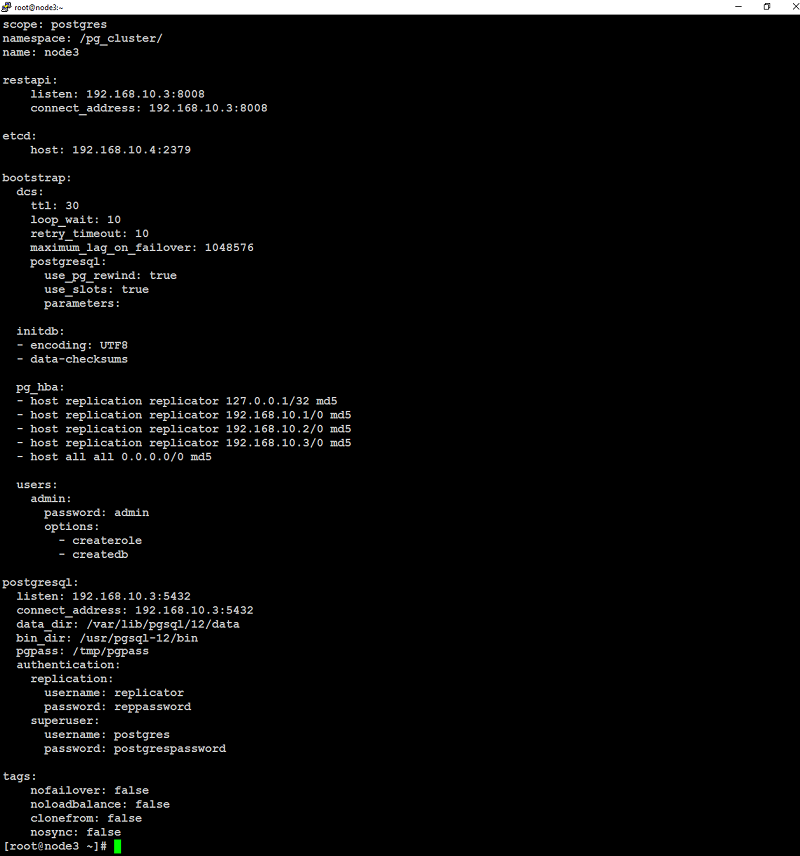
and below is from node3:
Make sure you have performed all of the above steps on each node those are designated for postgresql and patroni (node1, node2, node3 in our case) before going to next step of installing and configuring etcd.
Installing etcd
Etcd is a fault-tolerant, distributed key-value store that is used to store the state of the postgres cluster. Using Patroni, all of the postgres nodes make use of etcd to keep the postgres cluster up and running.
For sake of this guide we will use a single-server etcd cluster. However, in production, it may be best to use a larger etcd cluster so that one etcd node fails, it doesn’t affect your postgres servers.
Type below command to install etcd on node that is designated for etcd (node4 in our case):
Configuring etcd
At this point, you need to edit the /etc/etcd/etcd.conf file like below:uncomment by removing # from the following highlighted configuration parameters and make sure you replace ip address of the etcd node with yours:
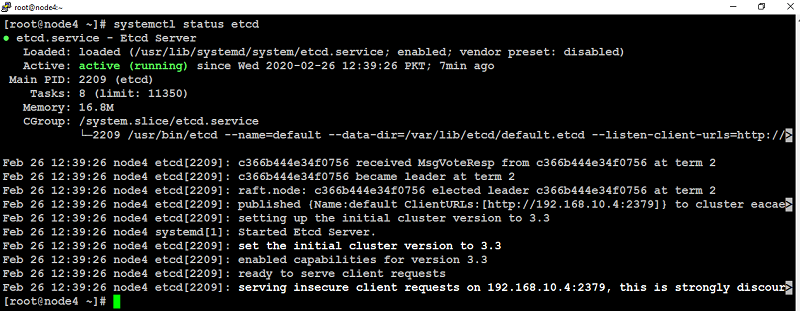
Save and close file when you are finished.Now start etcd service on (node4 in our case) to take changes in to effect with below command:
If everything goes well, you will see the output similar to like below screenshot:
Starting Patroni At this point, you need to start patroni service on your first node (node1 in our case):
If everything was set up correctly, you will see the output similar to like below screenshot.
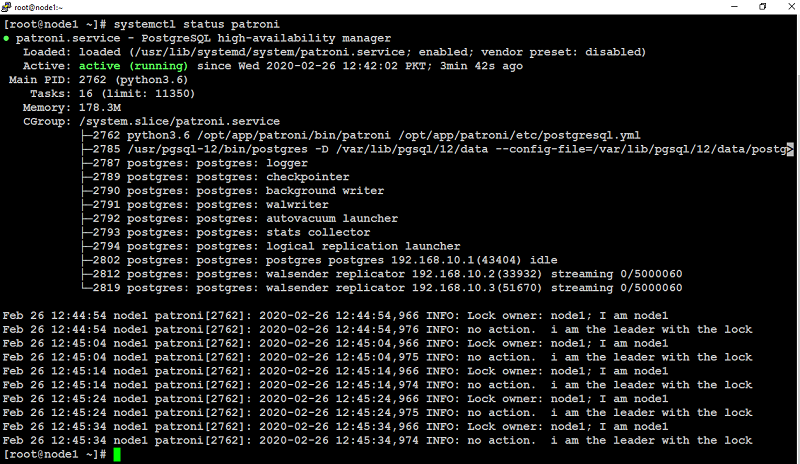
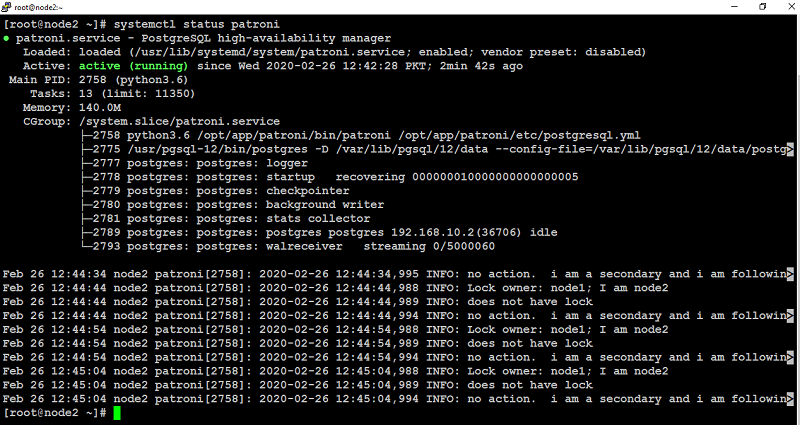
When starting patroni on subsequent nodes, (node2, node3 in our case) the output will look similar to like below:
Output from node3:
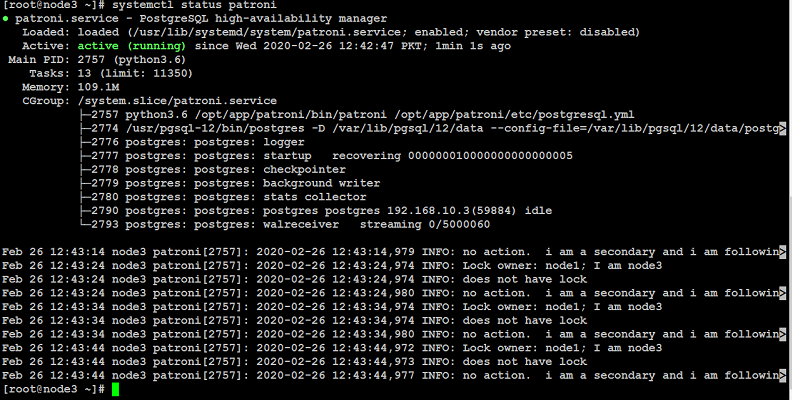
Make sure patroni service is running on each node (node1, node2, node3 in our case) before going to next step of installing and configuring haproxy.
Installing HAProxy
When developing an application that uses a database, it can be cumbersome to keep track of the database endpoints if they keep changing. Using HAProxy simplifies this by giving a single endpoint to which you can connect the application.
HAProxy forwards the connection to whichever node is currently the master. It does this using a REST endpoint that Patroni provides. Patroni ensures that, at any given time, only the master postgres node will appear as online, forcing HAProxy to connect to the correct node.
Configuring HAProxy
With the Postgres cluster set up, you need a method to connect to the master regardless of which of the servers in the cluster is the master. This is where HAProxy steps in.
All Postgres clients (your applications, psql, etc.) will connect to HAProxy which will make sure you connect to the master node in the cluster.
Take the backup of original file first with below command:
Remove everything from this file, add below configuration parameters but make sure you replace highlighted text with yours:
Save and close file when you are finished.
Now start HAProxy to take changes into effect with the below command:
You will see the output similar to like below screenshot. 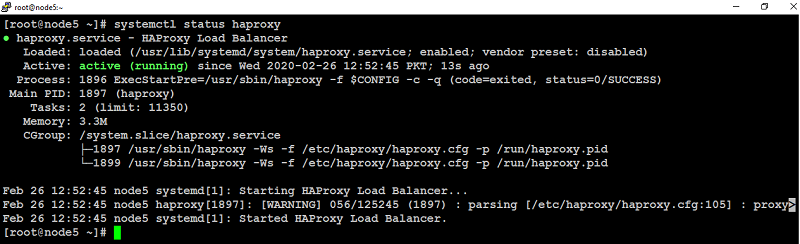
Testing Postgres HA Cluster Setup
Connect Postgres clients to the HAProxy IP address of the node on which you installed HAProxy (in this guide, 192.168.10.5) on port 5000 to verify your HA Cluster setup.

As you can see in above screenshot, client machine is able to make connection to postgres server via haproxy.
You can also access HAProxy node (192.168.10.5 in our case) on port 7000 using any of your preferred web browser to see your HA Cluster status on HAProxy dashboard like below:
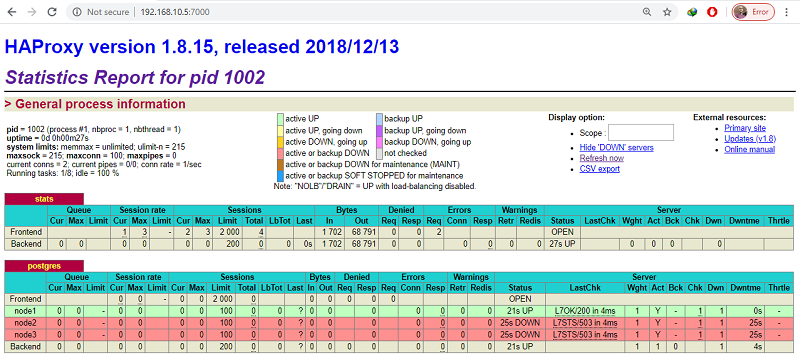
As you can see in above screenshot, the (node1) row is highlighted in green. This indicates that (node1 192.168.10.1) is currently acting as the master.
If you kill the primary node with systemctl stop patroni command or by completely shutting down the server, the dashboard will look similar to like below:
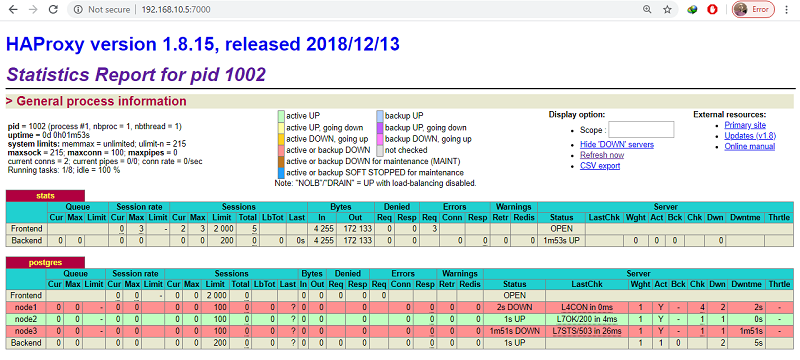
In the postgres section in above screenshot, the (node1) row is now red and the (node2) row is highlighted in green. This indicates that (node2 192.168.10.2) is currently acting as the master.
Note: In this case, it just so happens that the second Postgres server is promoted to master. This might not always be the case if you have more than two nodes in cluster. It is equally likely that the third server may be promoted to master.
When you bring up the first server, it will rejoin the cluster as a slave and will sync up with the master.
Wrapping up
You now have a robust, highly available Postgres cluster ready for use. While the setup in this tutorial should go far in making your Postgres deployment highly available, here are few more steps you can take to improve it further:
Use PgBouncer to pool connections.
Add another HAProxy server and configure IP failover to create a highly available HAProxy cluster.